Economics
ResumAI
Researchers had millions of cover letters paired with the job postings they were written for and no reliable way to measure whether each letter actually addressed the job. Traditional text analysis couldn’t judge that kind of fit, and the LLM-based approach that could was built for hundreds of observations, not millions.
What changed
The team can now score millions of cover letter–job posting pairs for quality and relevance using LLMs with confidence that the results are consistent today and reproducible years from now. The pipeline runs each pair through an open-weight model, scores it multiple times to verify stability, and scales across the full dataset. A validation interface lets the research team check the model’s judgments against their own.
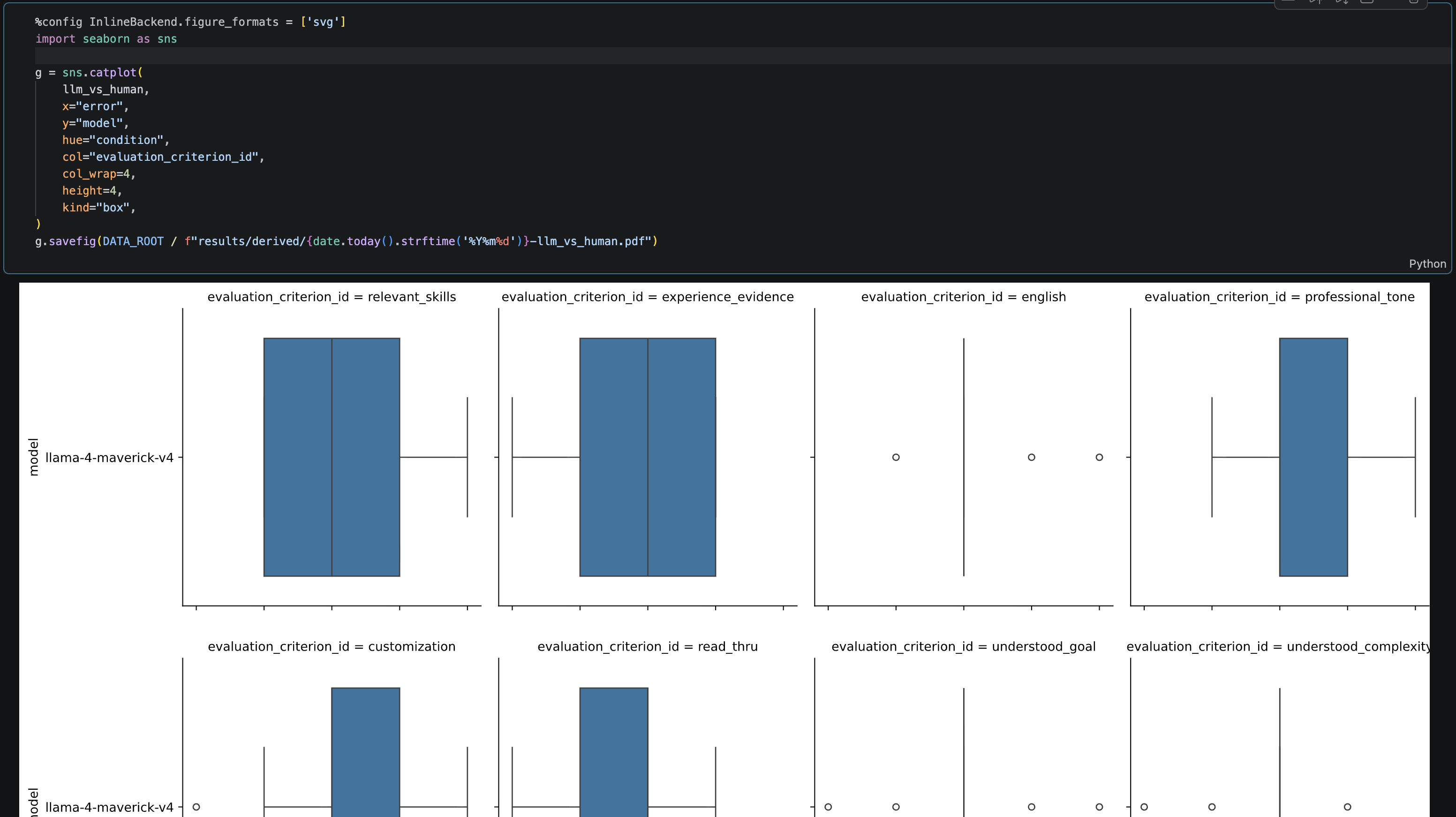
Scoring pipeline
An inference pipeline that sends millions of cover letter–job posting pairs through a large language model with structured prompts, runs each pair multiple times to measure score consistency, and logs everything for reproducibility. Designed to scale from a development set of 1,000 to a production set of 5 million.
Validation interface
A scoring UI that lets the research team manually evaluate a sample of pairs against the model’s output — the human check that gives them confidence the automated scores reflect real quality differences.
Reproducibility by design
Commercial LLM providers routinely retire models, which can make published results impossible to reproduce. The pipeline is built around open-weight models so the team controls versioning so that the same analysis will return comparable results whether it’s run tomorrow or in five years.